
# Using Data Stores
WARNING
This feature is in beta. There might be changes while we prepare it for a full release.
If you have any feedback on the Python runtime, please let us know in our community (opens new window).
You can store and retrieve data from Data Stores in Python without connecting to a 3rd party database.
Add a data store as a input to a Python step, then access it in your Python handler with pd.inputs["data_store"].
def handler(pd: "pipedream"):
# Access the data store under the pd.inputs
data_store = pd.inputs["data_store"]
# Store a value under a key
data_store["key"] = "Hello World"
# Retrieve the value and print it to the step's Logs
print(data_store["key"])
# Adding a Data Store
In the inputs select the Add Data Store option.
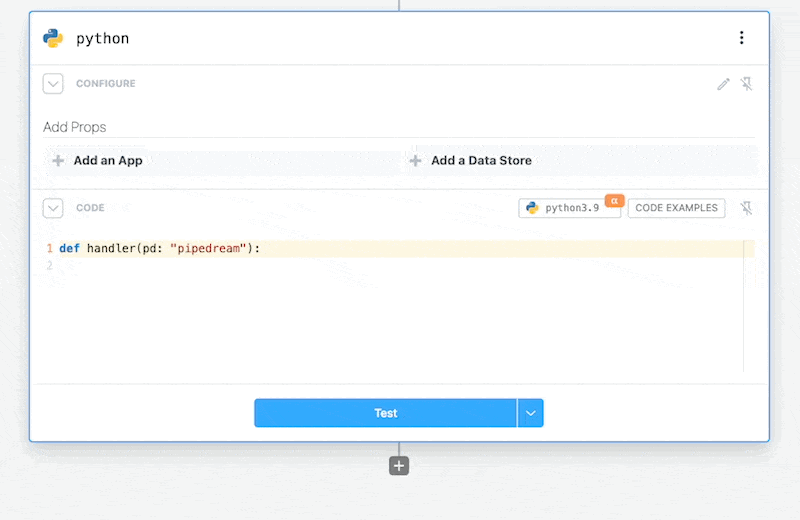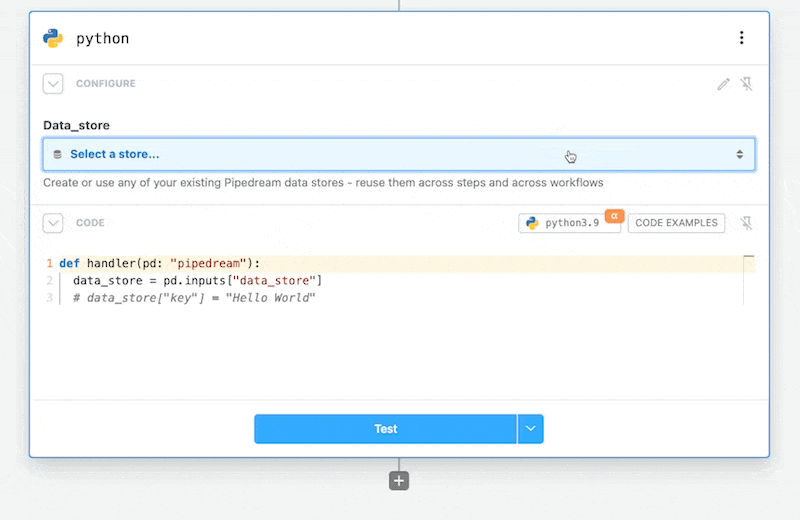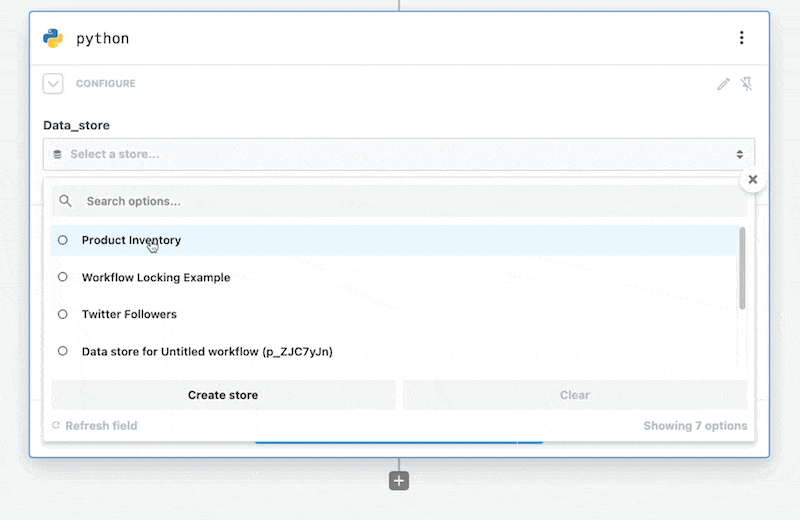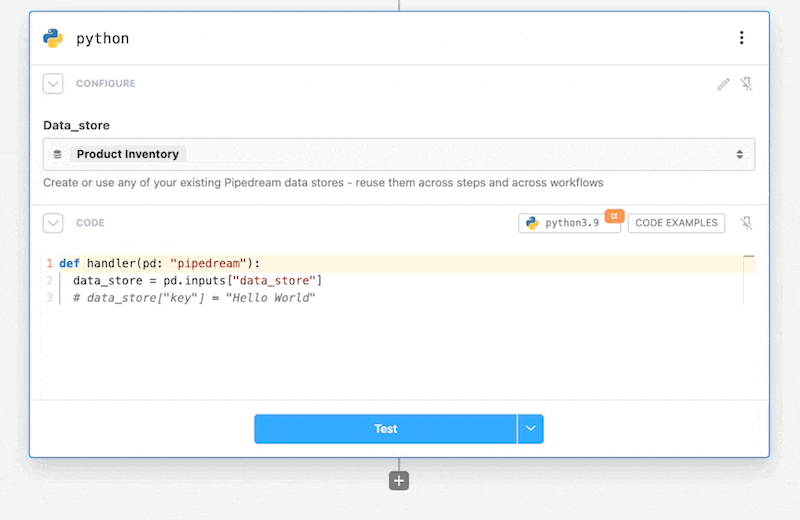
This will add the selected Data Store to your Python code step.
# Saving data
Data Stores are key-value stores. Saving data within a Data Store is just like setting a property on a dictionary:
from datetime import datetime
def handler(pd: "pipedream"):
# Access the data store under the pd.inputs
data_store = pd.inputs["data_store"]
# Store a timestamp
data_store["last_ran_at"] = datetime.now().isoformat()
# Retrieving keys
Fetch all the keys in a given Data Store using the keys method:
def handler(pd: "pipedream"):
# Access the data store under the pd.inputs
data_store = pd.inputs["data_store"]
# Retrieve all keys in the data store
keys = pd.inputs["data_store"].keys()
# Print a comma separated string of all keys
print(*keys, sep=",")
# Checking for the existence of specific keys
If you need to check whether a specific key exists in a Data Store, use if and in as a conditional:
def handler(pd: "pipedream"):
# Access the data store under the pd.inputs
data_store = pd.inputs["data_store"]
# Search for a key in a conditional
if "last_ran_at" in data_store:
print(f"Last ran at {data_store['last_ran_at']}")
# Retrieving data
Data Stores are very performant at retrieving single records by keys. However you can also use key iteration to retrieve all records within a Data Store as well.
TIP
Data Stores are intended to be a fast and convienent data storage option for quickly adding data storage capability to your workflows without adding another database dependency.
However, if you need more advanced querying capabilities for querying records with nested dictionaries or filtering based on a record value - consider using a full fledged database. Pipedream can integrate with MySQL, Postgres, DynamoDb, MongoDB and more.
# Get a single record
You can retrieve single records from a Data Store by key:
def handler(pd: "pipedream"):
# Access the data store under the pd.inputs
data_store = pd.inputs["data_store"]
# Retrieve the timestamp value by the key name
last_ran_at = data_store["last_ran_at"]
# Print the timestamp
print(f"Last ran at {last_ran_at")
Alternatively, use the data_store.get() method to retrieve a specific key's contents:
def handler(pd: "pipedream"):
# Access the data store under the pd.inputs
data_store = pd.inputs["data_store"]
# Retrieve the timestamp value by the key name
last_ran_at = data_store.get("last_ran_at")
# Print the timestamp
print(f"Last ran at {last_ran_at")
TIP
What's the difference between data_store["key"] and data_store.get("key")?
data_store["key"]will throw aTypeErrorif the key doesn't exist in the Data Store.data_store.get("key")will instead returnNoneif the key doesn't exist in the Data Store.data_store.get("key", "default_value")will return"default_value"if the key doesn't exist on the Data Store.- :::
# Retrieving all records
You can retrieve all records within a Data Store by iterating over all keys within the Data Store.
For example, use the data_store.keys() method to retrieve all keys, then iterate over each to build a dictionary of records:
def handler(pd: "pipedream"):
data_store = pd.inputs['data_store']
records = {}
keys = data_store.keys()
# iterate through all keys within the Data Store to generate a new dictionary
for key in keys:
records[key] = data_store[key]
return records
This code step example exports all records within the data store as a dictionary.
WARNING
The datastore.keys() method does not return a list, but instead it returns a Keys iterable object. You cannot export a data_store or data_store.keys() from a Python code step at this time.
Instead build a dictionary or list using the data_store.keys() method.
# Deleting or updating values within a record
To delete or update the value of an individual record, assign key a new value or '' to remove the value but retain the key.
def handler(pd: "pipedream"):
# Access the data store under the pd.inputs
data_store = pd.inputs["data_store"]
# Assign a new value to the key
data_store["myKey"] = "newValue"
# Remove the value but retain the key
data_store["myKey"] = ""
# Working with nested dictionaries
You can store dictionaries within a record. This allows you to create complex records.
However, to update specific attributes within a nested dictionary, you'll need to replace the record entirely.
For example, the code the below will not update the name attribute on the stored dictionary stored under the key pokemon:
def handler(pd: "pipedream"):
# The current dictionary looks like this:
# pokemon: {
# "name": "Charmander"
# "type": "fire"
# }
# You'll see "Charmander" in the logs
print(pd.inputs['data_store']['pokemon']['name'])
# attempting to overwrite the pokemon's name will not apply
pd.inputs['data_store']['pokemon']['name'] = 'Bulbasaur'
# Exports "Charmander"
return pd.inputs['data_store']['pokemon']['name']
Instead, overwrite the entire record to modify attributes:
def handler(pd: "pipedream"):
# retrieve the record item by it's key first
pokemon = pd.inputs['data_store']['pokemon']
# now update the record's attribute
pokemon['name'] = 'Bulbasaur'
# and out right replace the record with the new modified dictionary
pd.inputs['data_store']['pokemon'] = pokemon
# Now we'll see "Bulbasaur" exported
return pd.inputs['data_store']['pokemon']['name']
# Deleting specific records
To delete individual records in a Data Store, use the del operation for a specific key:
def handler(pd: "pipedream"):
# Access the data store under the pd.inputs
data_store = pd.inputs["data_store"]
# Delete the last_ran_at timestamp key
del data_store["last_ran_at"]
# Deleting all records from a specific Data Store
If you need to delete all records in a given Data Store, you can use the clear method.
def handler(pd: "pipedream"):
# Access the data store under the pd.inputs
data_store = pd.inputs["data_store"]
# Delete the entire contents of the datas store
data_store.clear()
WARNING
data_store.clear() is an irreversible change, even when testing code in the workflow builder.
# Viewing store data
You can view the contents of your data stores in your Pipedream dashboard (opens new window).
From here you can also manually edit your data store's data, rename stores, delete stores or create new stores.
# Workflow counter example
You can use a data store as a counter. For example, this code counts the number of times the workflow runs:
def handler(pd: "pipedream"):
# Access the data store under the pd.inputs
data_store = pd.inputs["data_store"]
# if the counter doesn't exist yet, start it at one
if data_store.get("counter") == None:
data_store["counter"] = 1
# Otherwise, increment it by one
else:
count = data_store["counter"]
data_store["counter"] = count + 1
# Dedupe data example
Data Stores are also useful for storing data from prior runs to prevent acting on duplicate data, or data that's been seen before.
For example, this workflow's trigger contains an email address from a potential new customer. But we want to track all emails collected so we don't send a welcome email twice:
def handler(pd: "pipedream"):
# Access the data store
data_store = pd.inputs["data_store"]
# Reference the incoming email from the HTTP request
new_email = pd.steps["trigger"]["event"]["body"]["new_customer_email"]
# Retrieve the emails stored in our data store
emails = data_store.get('emails', [])
# If this email has been seen before, exit early
if new_email in emails:
print(f"Already seen {new_email}, exiting")
return False
# This email is new, append it to our list
else:
print(f"Adding new email to data store {new_email}")
emails.append(new_email)
data_store["emails"] = emails
return new_email
# Data store limitations
Data stores are in beta. There may be changes to this feature while we prepare it for a full release.
Data Stores are only currently available in Node.js code steps. They are not yet available in other languages like Python, Bash or Go.
# Supported data types
Data stores can hold any JSON-serializable data within the storage limits. This includes data types including:
- Strings
- Dictionaries
- Lists
- Integers
- Floats
But you cannot serialize Modules, Functions, Classes, or other more complex objects.
# Querying records
You can retrieve up to 1,024 records within a single query.
The pd.inputs["data_store"].keys() function allow you to retrieve all keys from your data store. However, using this method with a data store with over 1,024 keys will result in a 426 error.