
# Python
Anything you can do in Python can be done in a Pipedream workflow. This includes using any of the 350,000+ packages available on PyPI (opens new window).
Pipedream supports Python v3.9 (opens new window) in workflows.
WARNING
Python steps are in beta. There might be changes while we prepare it for a full release.
If you have any feedback on the Python runtime, please let us know in our community (opens new window).
# Adding a Python code step
- Click the + icon to add a new step
- Click Custom Code
- In the new step, select the
pythonlanguage runtime in language dropdown
# Python Code Step Structure
A new Python Code step will have the following structure:
# The pipedream package includes helpers to use exported data from other steps, as well as export data from this step
from pipedream.script_helpers import (steps, export)
# Export a variable from this step named "message" containing the string "Hello, World!"
pd.export("message", "Hello, World!")
You can also perform more complex operations, including leveraging your connected accounts to make authenticated API requests, accessing Data Stores and installing PyPI packages.
- Install PyPI Packages
- Import data exported from other steps
- Export data to downstream steps
- Retrieve data from a data store
- Store data into a data store
- Access API credentials from connected accounts
# Logging and debugging
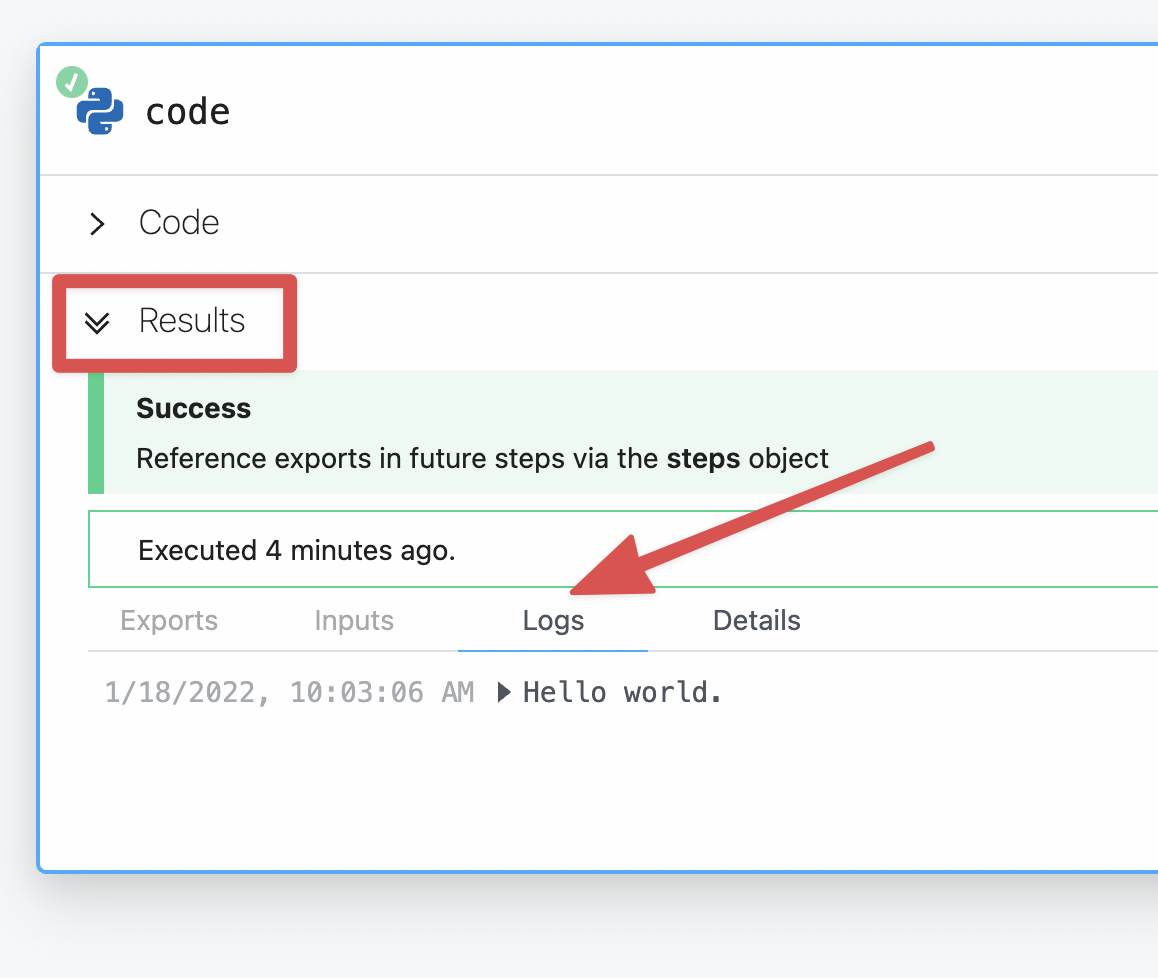
You can use print at any time in a Python code step to log information as the script is running.
The output for the print logs will appear in the Results section just beneath the code editor.
# Using third party packages
You can use any packages from PyPI (opens new window) in your Pipedream workflows. This includes popular choices such as:
requestsfor making HTTP requests (opens new window)sqlalchemyfor retrieving or inserting data in a SQL database (opens new window)pandasfor working with complex datasets (opens new window)
To use a PyPI package, just include it in your step's code:
import requests
And that's it.
No need to update a requirements.txt or specify elsewhere in your workflow of which packages you need. Pipedream will automatically install the dependency for you.
# If your package's import name differs from its PyPI package name
Pipedream's package installation uses the pipreqs package (opens new window) to detect package imports and install the associated package for you. Some packages, like python-telegram-bot (opens new window), use an import name that differs from their PyPI name:
pip install python-telegram-bot
vs.
import telegram
Use the built in magic comment system to resolve these mismatches:
# pipedream add-package python-telegram-bot
import telegram
# Making an HTTP request
We recommend using the popular requests HTTP client package available in Python to send HTTP requests.
No need to run pip install, just import requests at the top of your step's code and it's available for your code to use.
# Making a GET request
GET requests typically are for retrieving data from an API. Below is an example.
import requests
url = 'https://swapi.dev/api/people/1'
r = requests.get(url)
# The response is logged in your Pipedream step results:
print(r.text)
# The response status code is logged in your Pipedream step results:
print(r.status)
# Making a POST request
import requests
# This a POST request to this URL will echo back whatever data we send to it
url = 'https://postman-echo.com/post'
data = {"name": "Bulbasaur"}
r = requests.post(url, data)
# The response is logged in your Pipedream step results:
print(r.text)
# The response status code is logged in your Pipedream step results:
print(r.status)
# Sending files
You can also send files within a step.
An example of sending a previously stored file in the workflow's /tmp directory:
import requests
# Retrieving a previously saved file from workflow storage
files = {'image': open('/tmp/python-logo.png', 'rb')}
r = requests.post(url='https://api.imgur.com/3/image', files=files)
# Returning HTTP responses
You can return HTTP responses from HTTP-triggered workflows using the pd.respond() method:
def handler(pd: 'pipedream'):
pd.respond({
'status': 200,
'body': {
'message': 'Everything is ok'
}
})
Please note to always include at least the body and status keys in your pd.respond argument. The body must also be a JSON serializable object or dictionary.
WARNING
Unlike the Node.js equivalent (opens new window), the Python pd.respond helper does not yet support responding with Streams.
TIP
Don't forget to configure your workflow's HTTP trigger to allow a custom response. Otherwise your workflow will return the default response.
# Sharing data between steps
A step can accept data from other steps in the same workflow, or pass data downstream to others.
# Using data from another step
In Python steps, data from the initial workflow trigger and other steps are available in the pd.steps object.
In this example, we'll pretend this data is coming into our workflow's HTTP trigger via POST request.
// POST <our-workflows-endpoint>.m.pipedream.net
{
"id": 1,
"name": "Bulbasaur",
"type": "plant"
}
In our Python step, we can access this data in the exports variable from the pd.steps object passed into the handler. Specifically, this data from the POST request into our workflow is available in the trigger dictionary item.
# The pipedream package includes helpers to use exported data from other steps, as well as export data from this step
from pipedream.script_helpers import (steps, export)
# retrieve the data from the HTTP request in the initial workflow trigger
pokemon_name = steps["trigger"]["event"]["name"]
pokemon_type = steps["trigger"]["event"]["type"]
print(f"{pokemon_name} is a {pokemon_type} type Pokemon")
# Sending data downstream to other steps
To share data created, retrieved, transformed or manipulated by a step to others downstream call the pd.export method:
# This step is named "code" in the workflow
from pipedream.script_helpers import (steps, export)
r = requests.get("https://pokeapi.co/api/v2/pokemon/charizard")
# Store the JSON contents into a variable called "pokemon"
pokemon = r.json()
# Expose the data to other steps in the "pokemon" key from this step
export('pokemon', pokemon)
Now this pokemon data is accessible to downstream steps within steps["code"]["pokemon"]
WARNING
You can only export JSON-serializable data from steps. Things like:
- strings
- numbers
- lists
- dictionaries
# Using environment variables
You can leverage any environment variables defined in your Pipedream account in a Python step. This is useful for keeping your secrets out of code as well as keeping them flexible to swap API keys without having to update each step individually.
To access them, use the os module.
import os
import requests
token = os.environ['AIRTABLE_API_KEY']
print(token)
Or an even more useful example, using the stored environment variable to make an authenticated API request.
# Using API key authentication
If an particular service requires you to use an API key, you can pass it via the headers of the request.
This proves your identity to the service so you can interact with it:
import requests
import os
token = os.environ['AIRTABLE_API_KEY']
url = 'https://api.airtable.com/v0/your-airtable-base/your-table'
headers { 'Authorization': f"Bearer {token}"}
r = requests.get(url, headers=headers)
print(r.text)
TIP
There are 2 different ways of using the os module to access your environment variables.
os.environ['ENV_NAME_HERE'] will raise an error that stops your workflow if that key doesn't exist in your Pipedream account.
Whereas os.environ.get('ENV_NAME_HERE') will not throw an error and instead returns an empty string.
If your code relies on the presence of a environment variable, consider using os.environ['ENV_NAME_HERE'] instead.
# Handling errors
You may need to exit a workflow early. In a Python step, just a raise an error to halt a step's execution.
raise NameError('Something happened that should not. Exiting early.')
All exceptions from your Python code will appear in the logs area of the results.
# Ending a workflow early
Sometimes you want to end your workflow early, or otherwise stop or cancel the execution of a workflow under certain conditions. For example:
- You may want to end your workflow early if you don't receive all the fields you expect in the event data.
- You only want to run your workflow for 5% of all events sent from your source.
- You only want to run your workflow for users in the United States. If you receive a request from outside the U.S., you don't want the rest of the code in your workflow to run.
- You may use the
user_idcontained in the event to look up information in an external API. If you can't find data in the API tied to that user, you don't want to proceed.
In any code step, calling pd.flow.exit() will end the execution of the workflow immediately. No remaining code in that step, and no code or destination steps below, will run for the current event.
def handler(pd: 'pipedream'):
return pd.flow.exit()
print("This code will not run, since pd.flow.exit() was called above it")
You can pass any string as an argument to pd.flow.exit():
def handler(pd: 'pipedream'):
return pd.flow.exit('Exiting early. Goodbye.')
print("This code will not run, since pd.flow.exit() was called above it")
Or exit the workflow early within a conditional:
def handler(pd: 'pipedream'):
# Flip a coin, running pd.flow.exit() for 50% of events
if random.randint(0, 100) <= 50:
return pd.flow.exit()
print("This code will only run 50% of the time");
# File storage
You can also store and read files with Python steps. This means you can upload photos, retrieve datasets, accept files from an HTTP request and more.
The /tmp directory is accessible from your workflow steps for saving and retrieving files.
You have full access to read and write both files in /tmp.
# Writing a file to /tmp
import requests
# Download the Python logo
r = requests.get('https://www.python.org/static/img/python-logo@2x.png')
# Create a new file python-logo.png in the /tmp/data directory
with open('/tmp/python-logo.png', 'wb') as f:
# Save the content of the HTTP response into the file
f.write(r.content)
Now /tmp/python-logo.png holds the official Python logo.
# Reading a file from /tmp
You can also open files you have previously stored in the /tmp directory. Let's open the python-logo.png file.
import os
with open('/tmp/python-logo.png') as f:
# Store the contents of the file into a variable
file_data = f.read()
# Listing files in /tmp
If you need to check what files are currently in /tmp you can list them and print the results to the Logs section of Results:
import os
# Prints the files in the tmp directory
print(os.listdir('/tmp'))
WARNING
The /tmp directory does not have unlimited storage. Please refer to the disk limits for details.